
Identifying tables in documents and decoding their structure is one of the biggest challenges in automated document analysis. Since we often run our information extraction engine on documents containing tables, we face this challenge very often. Therefore, we decided to research the ideal machine learning algorithms to detect and recognize tables in documents.
Analyzing tables with a machine learning model is a difficult task. Tables in documents come in very different shapes and sizes. Some have visible lines, some do not. Some have bold text for headers, others use background colors. Cells may span multiple columns and rows, and if you work with non-native PDF documents, the scanned images can be distorted.

State of the art: neural networks
Until recently, researchers tried to find and structure tables with heuristic approaches. They applied rule-based systems that focused on the physical and logical structures of tables to detect and recognize table information. But since the rise of artificial intelligence, new methodologies have emerged. Current research now focuses on machine learning approaches to analyze tables, often with Convolutional Neural Networks (CNN) as core components. Since there are already quite a few good image recognition models available, researchers sometimes also tweak these models for table analysis.
To identify the best fitting algorithms for table detection and recognition in documents, we first evaluated dozens of recent research papers. After studying various methods, we decided to use a neural network for both table detection and recognition. As a basis for our table detection system, we used a Deformable Faster R-CNN as described in this paper. For table recognition, we built a custom pipeline with a Deep Graph CNN at its core. The DGCNN is proposed in this publication. In both cases, the approaches presented in the papers served us as a baseline for the networks we built and trained for our specific use case.
Building training sets
At least as important as deciding on the right algorithms for the task was finding the right training data to train them. Since our two networks were not pre-trained, we had to build large and reliable training sets for both of them.
We gathered the training data from various open-source datasets. Then, we sorted the data in two training sets per network. The larger training set for the initial training of the detection network consisted of 300,000 images of real documents which had been labelled automatically. The smaller dataset for the more elaborated training contained 7,000 human-labelled data samples from various table analysis competitions available online.
For the recognition network, we put together a large set of automatically labelled images containing 150,000 synthetical and 90,000 real samples, and a small set with just 500 human-labelled documents. The training sets for the recognition model were smaller than the ones for the detection model because there was less suitable data available.
Building the detection network
As mentioned above, we used a Deformable Faster R-CNN model for table detection. This network created detailed feature maps for the document pages we fed it. Following this, the second part of the neural network studied the patterns in these feature maps to give us information about whether there was a table in a page or not, and where it was located.
The detection network could be built with comparatively little effort. For the table recognition network, it was different. Since we did not just need to find the borders of a table, but the coordinates and the content of each individual cell in a table, we needed a more specialized system.
Building a pipeline for the recognition network
We decided to set up a dedicated pipeline with a Deep Graph Convolutional Neural Network (DGCNN) as its centerpiece. The first part of this pipeline was our detection network, which extracted the tables from the documents as an image. Then, we processed the images with an OCR engine to identify all the words and their coordinates. The OCR information was combined with other feature information we extracted by re-running parts of the detection network on the table images. In this way, we received a graph with all the words and their features as vertices for each table.
This graph we ran through the DGCNN, and it examined the edges between random pairs of words to decide whether they belonged to the same cell, column and/or row. As soon as we knew how the content was organized in cells, columns and rows, we could build data structures that represented our tables.
Better results than ICDAR 2019 leaders
After training our algorithms on all the training sets we had prepared, we compared our results to those of other models. As a benchmark, we used the leaderboard of the 2019 Competition on Table Detection and Recognition in Archival Documents organized by the International Conference on Document Analysis and Recognition (ICDAR). The winners of the ICDAR competition reach higher F1 scores than commercial tools and are considered world class.
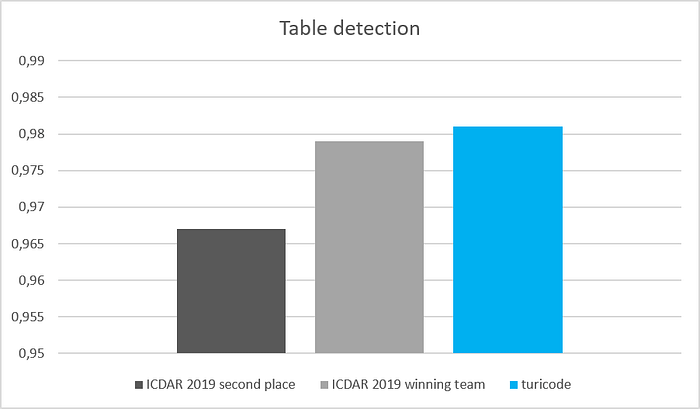

When we evaluated our networks with the test data provided by ICDAR, we noted that we had outperformed all benchmark models on the leadership board for both table detection and table recognition. While the best team on the table detection track of the competition reached an F1 score of 0.97 with a baseline IoU of 0.6, we reached 0.98. On the table recognition track, we were even more ahead with an F1 of 0.45 compared to an F1 of 0.37 by the winning team with a baseline IoU of 0.6. The results for the recognition track are generally lower because for this task, ICDAR only provided a test set and no training set, and the evaluation was more complex than on the detection track.
Pushing the state of the art
By now, our table analysis systems are integrated into our information extraction engine. Our research team is still working on improving the networks even more and training them with more and better data. In this way, we will improve the quality of data extraction from a wide range of documents for all industries, from bank and financial statements to laboratory reports and application forms up to table-based questionnaires.
To learn more about Intelligent Document Processing (IDP) visit acodis.io
